There are generally five types of indexes that can be created in Postgres => B-Tree, Hash, GIN, GiST and SP - GiST. The first two indexes are used for normal data type like integer, string etc. while the last three are used on more complex data types like geo data, hash etc.
In this post I am going to talk about the first two data types:
 A B-Tree index is created using a self balancing tree data type. Think of it as a binary search tree which balances itself when a node is added, deleted or modified.
A B-Tree index is created using a self balancing tree data type. Think of it as a binary search tree which balances itself when a node is added, deleted or modified.
 The entries in B-Tree are sorted. This enables us to use the index in range queries such as >= and <=. Interestingly query planner can use B-Tree index for null conditions. Another advantage of this index is that the values can be retrieved in a sorted order much faster compared to simple scan.
The entries in B-Tree are sorted. This enables us to use the index in range queries such as >= and <=. Interestingly query planner can use B-Tree index for null conditions. Another advantage of this index is that the values can be retrieved in a sorted order much faster compared to simple scan.
 A hash index is based on the concept of hashing. Basically you use a hash function which takes the query as the key and returns the address of the data being searched. Because of using hash functions they've a time complexity of O(1).
A hash index is based on the concept of hashing. Basically you use a hash function which takes the query as the key and returns the address of the data being searched. Because of using hash functions they've a time complexity of O(1).
In hash index it all boils down to hash functions. The database engine must ensure that hash functions map to correct values for an input. Also it needs to avoid collisions i.e. two different inputs should not return the same address.
Hash index can only be used for equality operators since the hash functions returns single value of a given input.
In this post I am going to talk about the first two data types:
B-Tree Index
A B-Tree index is created using a self balancing tree data type. Think of it as a binary search tree which balances itself when a node is added, deleted or modified.
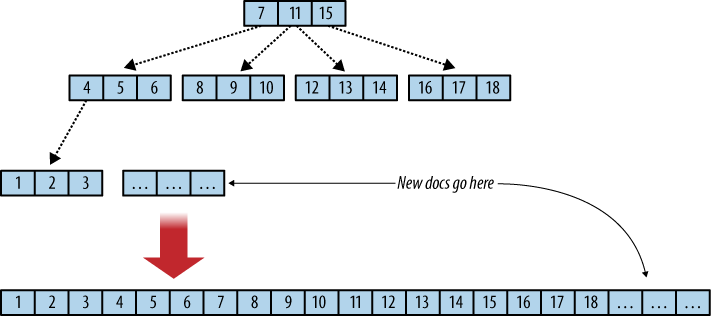
In the diagram below you'll notice a balanced tree
which represents the index. The docs are memory addresses which are pointed by a leaf node.
So if you want to get a document you've to search down the tree till you reach a leaf node and then access the document. Since the height of a tree is logN the time complexity for getting a record is logN.
The entries in B-Tree are sorted. This enables us to use the index in range queries such as >= and <=. Interestingly query planner can use B-Tree index for null conditions. Another advantage of this index is that the values can be retrieved in a sorted order much faster compared to simple scan.Advantages
- Can be used for equality and comparison operators(>=, <=).
- Null conditions like IS NULL can also use this index.
- Order by is much faster using this index.
Disadvantages
- Works better for dataset having more distinct values. Because lets say you have 10000 records of comic of which 5000 have name "dibert" and the other 5000 have distinct name, now you want to search "dilbert" edition 66 so you apply binary search to filter dilbert comics and then you do linear search for edition 66.
- Performs slower when the resultset queried is large, generally > 10% of table.
Hash Index
In hash index it all boils down to hash functions. The database engine must ensure that hash functions map to correct values for an input. Also it needs to avoid collisions i.e. two different inputs should not return the same address.
Hash index can only be used for equality operators since the hash functions returns single value of a given input.
Advantages
- Hash Index have a constant(O(1)) time complexity.
- The creation time for Hash index is very less since you don't need to order.
Disadvantages
- Not suitable for comparison operators.
- Not transaction safe. If there is a crash then you need to rebuild the index.
- Hash indexes allows table to grow until a size reached after which it has to be reindexed.
Comments
Post a Comment